In my last post I discussed one of my favorite new features in SQL Server OVER the last few versions. I also capitalized an entire word as if I were shouting it at you. REST assured that there is more method() than madness in this. In this CASE (stop please) I was alluding to the introduction of window functions and the OVER clause.
Uncategorized
DATEADD(HOUR,DATEDIFF(HOUR,GETUTCDATE(),GETDATE()),GETDATE())
There were a number of things brought into SQL Server OVER the past few versions that tickle me in such a way as to beg the question Why haven’t we been doing that all along? One of these I only gave a brief glance when I first saw it, much to my detriment. Datetimeoffset is a positively marvelous datatype. Not only does it allow us to store date and time values together with a precision of as little as 100 nano-seconds, but it can also be used to determine if two datetimeoffset values match across time zones with zero coded date math.
Unfortunately, only the latest version of SQL Server contains the DATETIMEOFFSETFROMPARTS. I say this is unfortunate because I am writing this from a SQL 2008 R2 machine, and the example that follows could be much more demonstrative the time zone sensitivity of the datetimeoffset data type if I hadn’t commented that code out. Nevertheless, let’s look at some comparison of datetime types.
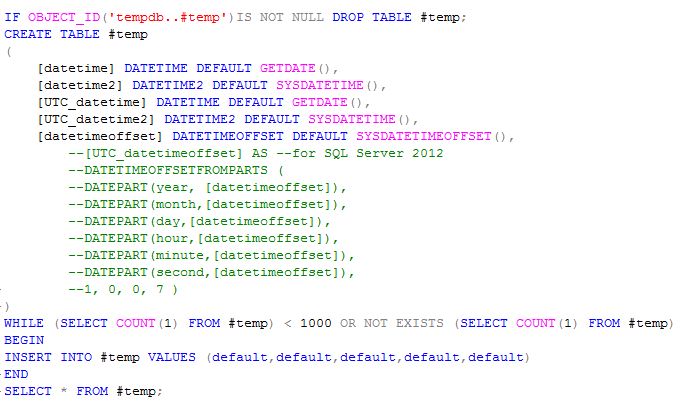
If we look at the output we can see the differences in the precision of the different datatypes. We can also see the time zone component to the datetimeoffset type. The standard date time data type cuts its digits off at the milliseconds’ place. This can be somewhat misleading in appearance. We’ll look at that later. But first let’s look at how fast these rows being written. We can also see from this result set that even at 100 nanoseconds precision we really can’t count on more precise time to uniqueify our rows. Perhaps, in a later post we’ll discuss TIMESTAMPS.
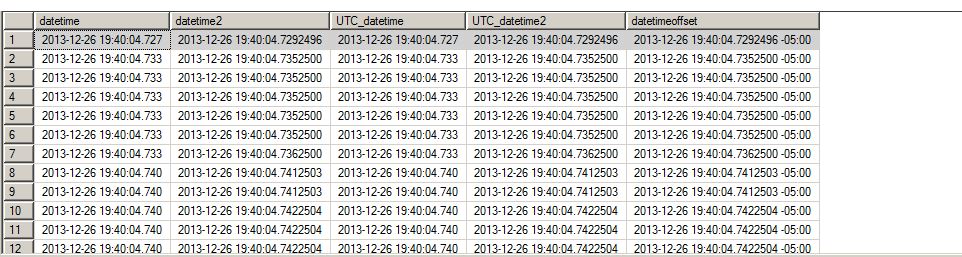
If we look closer at these values we’ll notice something. The right most digit in each and every value is limited to just a few numbers. In the case of the datetime values, I have come to understand that we can actually only capture 1/300th of a second as opposed to 1/1000th. As for the more precise data types it is unfortunate that in addition to leaving my SQL 2012 instance at work, I left my Cesium clock at the gym. That of course means, that I lack the tools to accurately determine how many nano-seconds precision we are realizing with our ability to store 100-nanoseconds.
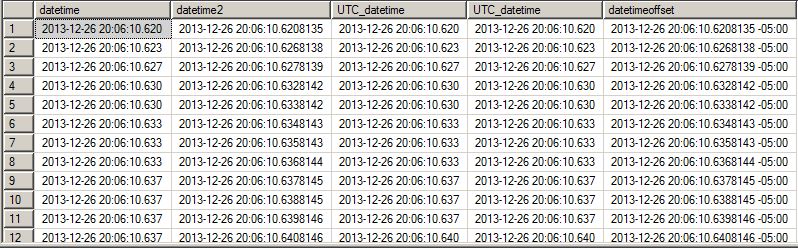
Its getting close to 2013-12-26 20:30:10.6208135 -05:00 and I am trying to keep these posts short and too the point, in that meandering way that whets your whistle for more (I hope). Speaking of whetting your whistle, look at this version of the above with a TIMESTAMP, which is not to be confused with a TIMESTAMP.
Big Data and the Role of Intuition
A recent issue of the Communications of the Association for Computing Machinery (12/2013 Vol.56 No.12, Dhar) paraphrases the core engineering dilemma of big data analytics as being one of the transition from retrieving data that matches patterns to discovering patterns that match data. More than anything I believe that intuition will remain a guiding factor in this for some time to come. The nature of unstructured data is one that must be tamed by finding structures that may only apply to a small portion of a big data set, but nonetheless provide more valuable information than those patterns found for pattern’s and not purpose’s sake.
That’s not a recursion. This is a recursion.

I may only be an expert of sorts in computer information systems as opposed to a computer scientist, and one specializing in algorithms at that, but I’d like to think I know the difference between iterating on row set that diminishes with each iteration, and set constrained self calling operation. I am also pretty sure that iterating on a row set that diminishes with each iteration is parent form of a for each type iteration. I do know that SQL Server 2012 introduces for us a deployment model that makes the business of building recursive SSIS packages wholly more tenable.
The project based deployment model allows us to reference our packages in development. This is a welcome change as it allows us to make better use of a more modular approach to package development. One of the ways that this is manifested is in the Execute package task. Instead of creating a connection manager of either a SQL Server or File System type, you can use an internal reference. In SQL Server 2012 an execute package task can be used to call a package that is either internally referenced in the same project as the parent package, or externally referenced. An externally referenced package is essentially the only reference type in SQL 2008 R2. This requires the use of a connection manager which will need to change if we are developing anywhere other than our production environment, which if you do, you really shouldn’t.
Beyond being able to call packages stored in the project we are working in the internally referenced package call allows us to do something that is simply amazing. We can call the package we are building. That means that we can have a child package that can modify the parent package’s variable values as they are the same variables. In the example I have created a package that reads a list of packages and executes them asynchronously. I included annotations to help keep this relatively simple package conceptually simple.

The package begins with an Execute SQL Task. I use an expression(which we can see on the design space, new to SSDT) to set the disable parameter of this task. This is simply a test of the initialization parameter. If we are making the initial call to this package the parameter defaults to 1 which tells the populate Args SQL Task whether or not to run. For fun I pass the actual SQL to run to it through another parameter. Actually, it is quite a bit more than just fun but we will have to discuss environments, parameters and programmatic execution in package stores in later posts.
The next task is a scripting task in which I manipulate the array (I need to be mum on the specifics of this for various legal reasons I err on the side of caution for). I achieve two primary things by this task. The first and more obvious item accomplished is popping first argument off of the Args stack. The second is checking that there is at least one row left in the set (there are a lot of ways to skin this cat). If there isn’t we change our initialization value to -1. Otherwise we set it to continue.
Next we use a sequence container to assure that the previous steps have executed before we execute the remaining two in parallel. If we had an array length of zero for our Args set the -1 initialization parameter would disable this container and prevent the execution of its children members. Once it knows it’s disabled, the package completes its execution.
The next task is an execute package task. This simply executes the package we are in. We have access to and set the same variables with our actions. Since we have enforced precedence outside of the container and set our next Args and already disabled our Args population SQL Task, this task will inevitably lap our work task, allowing us to start all of our work without waiting for any of it to complete. If any of our work items are such that they require precedence constraints between them, we can engineer some sort of messaging service for them, or build parent packages that enforce the precedence between those packages and call them instead of their children.
Our final task is the one that performs the actual work. In this case I chose an execute process task that calls DTEXEC. Our Args set member retrieved in our script task is one of the parameters for the DTEXEC calls to packages that may have a different deployment model or project than our recursion. We could of just as easily used this approaches to spawn workers to operate on separate folders or servers.
Because some strings are code and some code contains strings that are code.
Not to dicker on about grammar and in particular grammatical flourishes in blog post ostensibly about syntactic inversions, but wouldn’t it be great if we allowed the title Because some strings are code and some codes contain strings that are code. I certainly do not intend to post about semantics proper, not to be confused with semantic web ontologies which is likewise a different topic and in many respects a different expert credential than I have been alluding to this past year.
Blogs I Follow, Found, Read, or Otherwise Link To
Blogs I Follow, Found, Read, or Otherwise Link To
Here I am making a blog post about adding blogs to the blogs I follow feature here on Word Press. With the pending New Year only a week or so away it dawns on me that I still don’t have the blog presence I resolved to in at least 3 of the last 5 new years. I have started and abandoned at least 3 blogs so far. I have tried to blog on databases in general, software development, systems administration, gardening, politics and various combinations thereof. I read as much as Blogging for Dummies as I could without buying a coffee refill at Barnes and Noble. I think I was reading at a venti level at that time. I am pretty sure it told me that one of the keys to getting good traffic to your site was by following blogs and linking to articles. It might also help to review a book.
How Marketers Can Avoid Big Data Blind Spots
I find it interesting that the short term sales gain doesn’t contribute to brand value. It would seem to me that barring a demographic that responds only to recent campaigns would the exposure lead to long term brand value. I’d imagine the proportion of short term gains to long term growth or leakage mitigation might be an important metric for the valuation of large datasets. The problem that arises from this, from the point of view of may data professional, is one of the valuation of large unstructured datasets. Big data tends to be unstructured and requires processing to extract patterns that can be used for analysis. This processing incurs costs that need to be justified.
How an Auction Can Identify Your Best Talent
As a database administrator I often find the swiftest route to the completion of development work often depends on the consumer of that work and the workflow through the departments. It seems that such an approach could be immensely beneficial as an approach to balancing workflow loads between departments with relatively interchangeable skillsets (at least the entry level). For example, software development, database administration, analytics, reporting, and systems administration will often have team members with skillsets that while more advanced in their specific discipline are sufficient for junior level work in other disciplines. Competing for project tasks with valuations that would presumably climb with the scarcity of the skills required to complete them would enable other departments the opportunity to add value providing lower level work that has the added benefit of strengthening the organization’s resilience as those portable skills grow sharper with use.
We Can Now Automate Hiring. Is that Good?
So it is a question of monetizing the strategic value of talent acquisition (and retention) and coping with the tactical exposure that sharing such valuations with external facing vectors favors.
Algorithms Won’t Replace Managers, But Will Change Everything About What They Do
How can we demonstrate to a machine that we are complimentary to it?
