Today’s email newsletter from Brent Ozar linked Flowing Data’s best of 2014 data visualization. Hidden among the bar charts and rose diagrams and the New York Times standard stunning collection of visualizations was Tyler Vigen’s Spurious Correlations. I am in awe, from the time that I found excuses not to correlate the population of wild asses and election results for a contest Tableau was sponsoring until I saw a graphic using Godzilla to compare military spending by country (guess who is Godzilla and who is a midsize high rise) I have been enamored by data visualization, and even more so when it is done to humorous effect. I particularly disturbed by possibility that someone might be particularly disturbed by the fact that for every billion dollars in sales at General Mills 2.3-2.5 women in California die by slipping and falling.
Author: thomaswmarshall
Love it Hate it
My last post touched on a specific SQL Server task and how a reduction of permission footprint can be realized by using SSIS instead of T-SQL. This is often the case with cross-server operations. The post also touched on my blogging habits. Who are we kidding I shoehorned SQL in at the end. I love SQL, of course I love problem solving more. SQL happens to be the tool that presents me with a cornucopia of problems I can solve. Without problems to solve I am often at a loss for the fuel of blog posts, of course with problems to solve I frequently have an NDA.
My last post also touched on the simplification that we need to focus on to make ourselves more accessible.
Slow Down Mr. Smarty Pants!
Another year is drawing to an end. That means it is time to review the successes and failures on my list of resolutions. It is also time to make new ones. On the plus side I have already met my commitment to at least one blog post per month average. I won’t have to put up a flurry of articles in the next week and a half to meet that resolution. I think I should modify my resolution next year such that I need to post more regularly.
Reviewing my posts I have noticed that I am following that advice that I post about what interests me.Of course, I have been told that I can be interested in things that don’t necessarily interest others. It’s not that people aren’t interested in database administration or SQL server; It’s that most people aren’t interested in more abstruse topics. At a recent board meeting of the Philadelphia SQL Server user’s group we were discussing speakers and topics. We wanted to be clear that we are seeking to bring in speakers that will bring our members to meetings.
To that effect I am going to stipulate for the coming year’s blog posts that I post about more accessible topics. I am also going to make it a point to articulate why my sometimes more advanced seeming efforts are not. One example comes to mind.
When you are trying to set up an automatic restore job and you want that job to start when the backups have finished. In order for a job to be started via a linked server the linked server account must own that job (it might also need to be a member of the target server role modified to be granted execute on sp_startjob). There must also be a connection such that it can read the backup tables to find the placement of the backup files. XP_dirtree of cmdshell can also be used to list existing files but they won’t fail the way attempting backup files that don’t exist (perhaps they got deleted, it would behoove you to notice this). If we were to use SSIS it would only need to be db_creator on the restore machine and db_reader on msdb on the backup machine, as well as have read file system permissions for the location of the backup. This is a smaller service area than would be needed to start remote jobs and read remotely, especially as it would be a single Windows login as opposed to two SQL Logins, and at least one Windows login (more if the SQL Agent account is not a domain account used by both machines).
#IoE The Internet of Everything (Things) #IoT
If you didn’t know it tech is rampant and wonton in its generation of buzzwords for all sorts of things, or more specifically for sexing up all sorts of things that are more than the sum of their parts. The singularity, Web 2.0, e-this, i-that, social, mobile, the cloud, big data, and the Internet of Everything (Things) to name a few. Sometimes these things overlap. Sometimes they overlap in a so many ways that a Venn diagram starts to need an expert algebraic topologies to explain. Lately, the buzz has been around the cloud, big data, and the internet of things. As a technology professional and in particular a database professional it is important to me to sort through the really cool things.
One of the things we now have an is internet of the light bulb. This is real unlike the hyper text coffee pot protocol which is a 16 year April fool’s joke the IETF created, or the Linux toaster which is a malware vector. Phillips Hue is a light bulb (system) that represents the culmination of incremental improvements to lighting bringing together a number of preexisting lighting features and adding them to an API. Hue combines, timers, dimmers, color, and circuit switching to provide a system that allows us to further take for granted one of the greatest technical achievements of the last millennium. That of course is the internet of things, at least the command side of it. I wonder if people have it in them to take their beverages according to a queue, or perhaps a locational aware protocol that starts my coffee when I approach the break room during a certain period of time.
Other things there are internets of will have sensors. These will write data somewhere. Lately, it looks like some Hadoop file system will be the standard. I wish I were more abreast of the internals the way a storage engineer would be so I could form a better opinion of why HFL would be a better choice than WAFL for writing streams. I suspect it has to do primarily with Map Reduce (at least public domain Map Reduce) only being implemented on Hadoop and MongoDB (and …). Of course if we need to respond to events in real time we need to put our event triggers upstream from storage.
SQL Server Files, Drives, and “Performance”
Last night after our monthly PSSUG meeting our presenter Jason Brimhall found himself waiting for a cab at Microsoft’s Malvern PA Office. Having waited for a taxi in Philly’s suburbs before I felt bad for his wait that might not end so I took it on myself to offer him a ride to the airport Marriot. On the drive I took it upon myself to ask his opinion on different strategies for allocating database files in SQL Server. This is a topic I find myself drawn to and I welcome the opportunities to hear other people’s (especially a Microsoft Certified Master’s) opinion on the subject.
I tend to find myself drawn to a simple approach that increases the number of files proportional to the size of the database. I admit that this is a matter of convenience and portability that has its limits. While Microsoft publishes some file numbers as the maximum (4,294,967,295) and the number above which issues may occur (50,000), a much lower number of files will tend to practical depending on needs. In one case I have encountered I found that at about 200GB I struggled to get reasonable copy and move speeds even with ESEUTIL. This was of course a single site scenario with fiber channel SAN as target and destination. Other scenarios require much smaller file sizes as well as other tools for copying (XCOPY, ROBOCOPY). Copies over a WAN (should be over a VPN\VLAN, but that is a different discussion Sebastian Meine could comment on as a segway to his presentation on new security roles in SQL Server)… copies over a WAN will traverse network segments of varying speeds, few if any of which will ever approach the throughput of fiber SAN. In these cases it is a matter of balancing the need for a manageable number of files and folders and keeping files small enough to copy. But for each of these cases it is important to note that the performance is being measured on the dimensions of speed of database file copy and file manageability (as an intersection of scripting for file and folder creation and the flexibility of the physical data model to make use of files), these are not frequently dimension of performance that our users notice.
Jason pointed out that from the point of view of user any significant query slowness will be perceived as an outage, and was a point added to his case against the separation of data and indexes into separate files specifically relevant to cases of piecemeal file based recovery. Our discussion started with my asking him his opinion on the comparative merits of creating separate database files for each processor (core) vs. using IO affinity masks to delegating IO related processing to a specific processor. I feel it important to note that some NUMA systems have separate IO channels for each NUMA node in which case IO affinity would deprive those member processors those channels (I think). Jason was supportive of allocating files per processor in the more general case. He mentioned that it wasn’t necessary (or always possible) to have separate disks for these files to realize performance.
What are you thoughts?
Are you familiar with the proportional fill algorithm?
What do you think about the impact of using solid state local disk in tempdb in 2012 FCI? or tiered storage?
Proportional fill reading:
http://sqlserver-performance-tuning.net/?p=2552
http://www.patrickkeisler.com/2013/03/t-sql-tuesday-40-proportional-fill.html
http://technet.microsoft.com/en-us/library/ms187087(v=SQL.105).aspx
Does that really need an app?
What feature does your app provide that cannot be provided via a mobile web site?
Kiwi Puts Its All-Purpose Wearable Up For Pre-Order, Aims To Be Everything To Everyone
Now your talking about wearables. Hype all you want about smart watches that only work with certain phones, but things like this (and perhaps cufflinks), and Martian Commander watches are what are going to make the difference. The new Mac Pro may be a revolution in design, that transforms a desktop computer into an objet d’art, but I doubt I could find a matching pair of shoes if someone called it a hat.
SQL SERVER – Copy Statistics from One Server to Another Server
I was watching SANMAN’s most recent video DEVOPS: Mission Impossible and it reminded me of Pinal Dave’s article here. THis is a great way to avoid moving data and diminish the weight of arguments for allowing development access to production databases and data.
New Year’s Resolutions
Like so many people I indulge in the tradition of casting off my inhibitions in preparation for casting off my bad habits as far into the New Year as can be predicted. At the very least I am going to attempt to take on or renew some good habits.
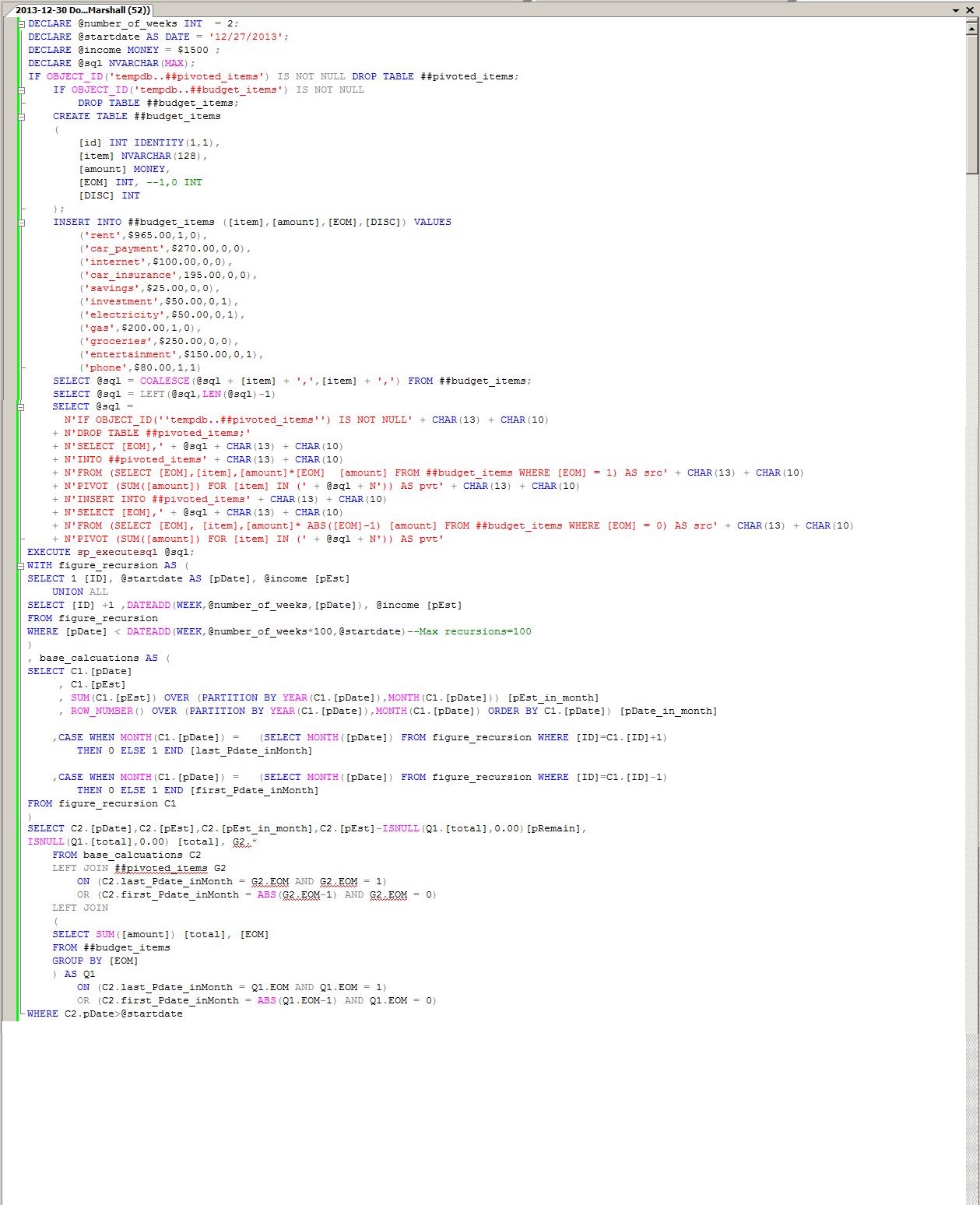
I am going to blog.
I am going to budget.
I am going to eat right.
I am going to exercise.
I am going to find ways to shoehorn SQL or NoSQL into each of those things.
It is to the effect of accomplishing the first, second, and fifth of these I am writing this post.
I bought this book from this guy who made a puzzle I was busy to solve, and now I think I know everything
In my last post I discussed one of my favorite new features in SQL Server OVER the last few versions. I also capitalized an entire word as if I were shouting it at you. REST assured that there is more method() than madness in this. In this CASE (stop please) I was alluding to the introduction of window functions and the OVER clause.
