In the course of developing the expertise I have made it a point to assert as the point several past posts I have encountered a number of philosophies regarding the comparative value of various areas of expertise capable of being applied in a manner such that they overlap competitively. I in this time made it a point to refrain from passing judgement prematurely favoring one methodology to another. It has been my experience that often enough the positions of opposing schools of thought on most any subject are such that they focus primarily on the strengths of their position neglecting concern for their weaknesses which oft as not are the strengths of the other. In short thesis and antithesis give rise to synthesis.
Having said that brings us to the specific example to which this particular generalization most immediately applies. Recently I was asked by a novice SSIS developer if there a way using only SSIS package tasks to display a result set such as to provide inline with the aggregated values the final aggregates. This is something that over time I have developed a reflex to provide an SQL solution to. For brevity’s sake I am glad the question was not one of a running total.
First let me show you the solution I provided in SSIS:

In the ETL Solution we join together the original source and the aggregate run against it. In SSIS this requires an additional sorting step. This sorting step is perfomed implicitly in SQL by the database engine. Generally speaking sorting is one of the most if not the most expensive operation that can be performed on a set of data, whether it is implied or explicitly commanded.

In either case we are performing the sorting of sets to be joined and in the SQL statement we are explicitly sorting the output. Of course results speak for themselves.
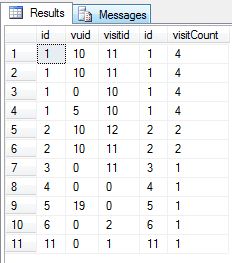

In the left image we see the output of the SQL Statement and in the right the output of the SSIS task. There are differences in the names these are primarily owing to a lack of rigor on my behalf regarding the naming. We can see from the outputs that the data values are identical for both approaches.
So why should we choose one approach over the other? What you may not have noticed earlier in this post is that the SSIS solution output shown is the consequence of my having added a data viewer to the data flow task’s merge join output. That is to say is that what you are seeing in “output” of the SSIS solution is the output of the extract and transformation steps in the extract, transform, load data flow and not the output of the ETL flow which would be a confirmation of the data being loaded while in debug mode or an entry in the sysjobhistory table should it be run as an SQL Agent job with logging enabled.
I have to apologize for the trickery though I think it appropriate to demonstrating the differences between the two technologies. A proper comparison would have had a SQL solution that looked like this:

You’ll note that if our only purpose was to select the data, using SSIS would be an inappropriate choice. However, since we are moving the data it becomes a question of establishing benchmarks for comparison of performance. Having said depending on the compatibility level of the database and surface area configurations we cannot connect between instances using the OPENDATASOURCE clause. That of course is just a cursory manner of saying, there exists numerous administrative issues related to the connecting data sources and the securitization as such that often make the business of ETL more complicated than questions of SQL statements and sort algorithms.

One of the considerations you alluded to that might making the choice of SSIS more tenable might be a question of systems resources available to the instance and the performance consequences of selecting and sorting data on that instance. An SSIS based solution can read out the data and perform the transformation operations on a separate server reducing the load on the source system.